On December 18, 2022, an exception occurred in Alibaba Cloud Hong Kong services. The Hong Kong server used by this site was also affected. Due to my incorrect alarm configuration, some domain names were not correctly switched and resolved, causing a small number of users to be unavailable for up to half an hour. However, the problem occurred in the Alibaba Cloud Hong Kong computer room for far more than an hour. According to my monitoring here, since 10:49 Beijing time, the HTTP and HTTPS services I run on Alibaba Cloud in Hong Kong are completely unavailable, and they are not restored until 20:46, with a total of 10 hours of downtime.
Incident Review
I found out that the Alibaba Cloud Hong Kong server was unavailable after I woke up in the morning. At first I thought it was blocked by a mysterious force, but after seeing the alarm email, I found that the Hong Kong server was also unavailable in other foreign regions.
Then I tested it and found that the host can be pinged, but cannot SSH up, and the HTTP/HTTPS service is also unavailable. In addition, yangxi.tech website services were also affected. Then I logged in to Route 53 in AWS China to check the alarms, and found that there were no alarms on Route 53 (both my guozeyu.com and yangxi.tech are using Route 53 in China). Looking at the recent monitoring, I found that I had a configuration error on Route 53, which caused the program to not actually monitor Hong Kong Alibaba Cloud…so I modified the monitoring rules. At this time, I logged into the AWS international zone, and found that the Aliyun Hong Kong monitoring in the international zone was alarming normally. I found that it started at 10:49, and all monitoring points around the world were unavailable.
Since the alarm in the AWS China region has been changed to correct by me at this time, automatic downtime switching has been performed at the DNS level according to the rules; moreover, the DNS TTL I configured before is only 120 seconds, so all my The website should be fully back to normal by 11:20. If there were no faulty alert rules, my site would not have been down for more than 5 minutes in total.
Then I logged in to my self-built Observium monitoring, and saw that the machine of Alibaba Cloud Hong Kong was down without any surprise. But I found that before the crash, the server’s CPU was 100%. I wondered if a program on my own server was stuck and took up all resources, making it seem that HTTP/HTTPS/SSH services were unavailable.
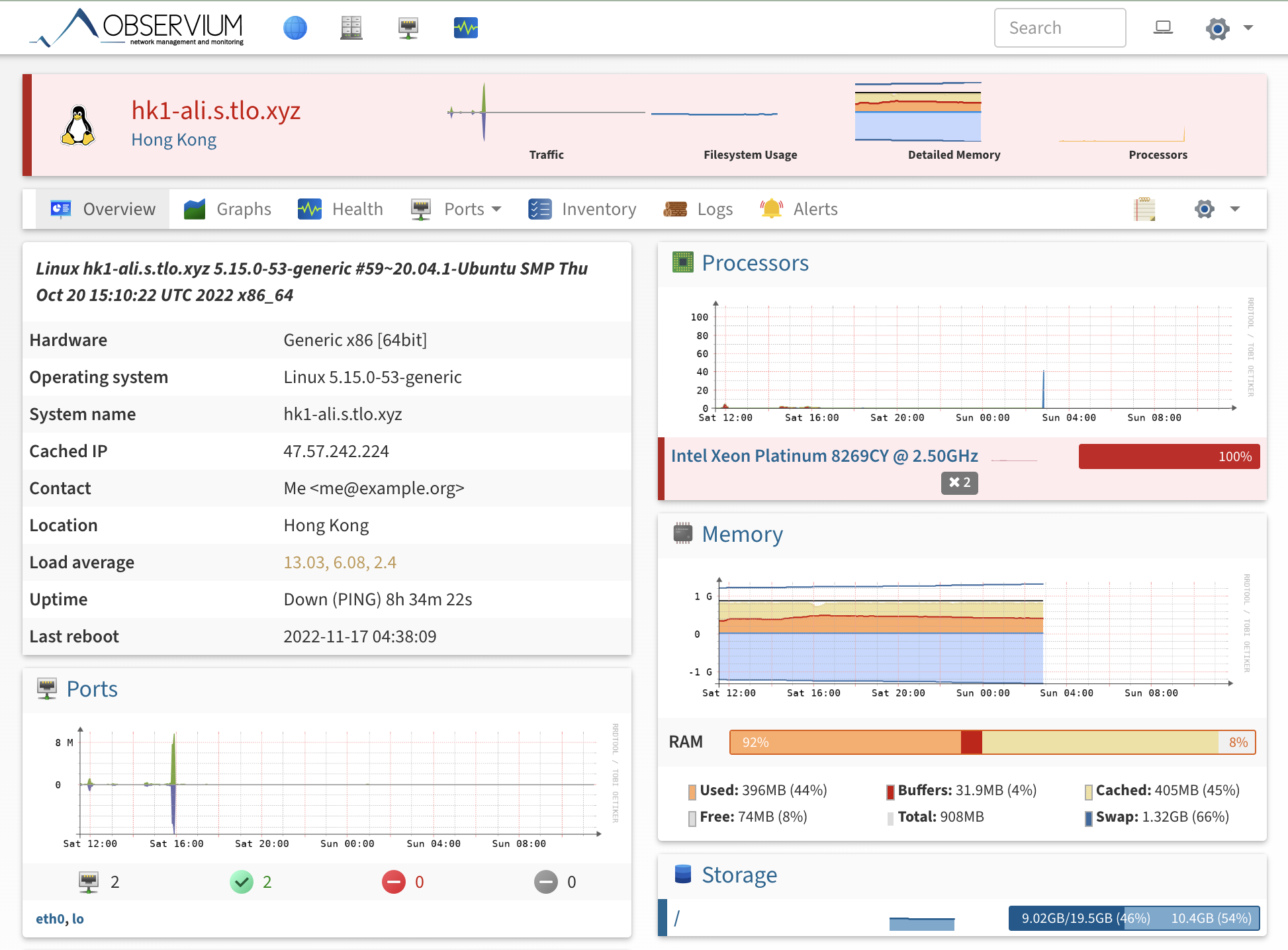
It is already 11:30 at this time, and I still think this is my own problem. After all, I have not received any email or phone reminder from Alibaba Cloud. So I logged into the Alibaba Cloud background and tried to restart. At this point I don’t have the option to force shutdown. As a result, the shutdown command has been executed for 10 minutes, and the machine still does not turn off. Usually when I use GCP, if the shutdown command is executed for more than two minutes, it will automatically perform a forced shutdown, so it is outrageous to execute a shutdown of 10 minutes at this time. Then I tried to send a work order, but I failed to enter the work order and was transferred to the online customer service. After I described the problem to the online customer service, no one responded. Then I tried to send a work order again, but no one responded to the work order. Just got a bot reply saying that on shutdown, Windows will perform a system update, which sometimes takes 10-15 minutes. Please contact customer service after waiting 20 minutes.
After about another half hour, the machine finally shut down successfully, but after several attempts, the machine would not start up. Even if I hit start, the machine goes to “Stopped” state after a while. At this time, I still thought it was my own problem, not Alibaba Cloud’s problem. I thought the system was damaged due to the forced shutdown just now, so I tried to take a snapshot of the existing cloud disk and try to roll it back. But something outrageous happened again, and I found that I couldn’t take snapshots at all! The progress of the snapshot is always at 0%.
At 11:55, I finally received a reply to the work order: “Hello! Alibaba Cloud monitoring found that the equipment in a computer room in Hong Kong was abnormal, which affected the use of cloud products such as cloud server ECS and cloud database polardb in availability zone C in Hong Kong. Alibaba Cloud The engineer is in urgent processing, I am very sorry for the inconvenience caused to your use, if you have any questions, please feel free to contact us.” Only then did I realize that this outage might not be my fault, and I gave up trying to restore the service myself.
The reply did not provide a solution, nor did it have an expected recovery time. It can be said that it just told me “this is a problem with our Alibaba Cloud”, and it did not substantially help restore the service.
About Alibaba Cloud
The most worthy complaint about this incident is that I have never received any relevant notification from Alibaba Cloud. Until now, I have not received any reminder from Alibaba Cloud about the service downtime in emails, text messages, and on-site messages. I believe that Alibaba Cloud has a lot of monitoring. I firmly believe that Alibaba Cloud already knew that there was a problem with my service and other people’s servers long before I found out that there was a problem with my service. But I don’t get any notification. The only thing that told me about the problem with Alibaba Cloud was that I sent a work order and asked it myself.
I think it is necessary for Alibaba Cloud to send relevant reminders to all affected and potentially affected customers. After 8 hours of continuous downtime without recovery, Alibaba Cloud still did not take the initiative to notify customers. It is really hard for me to doubt whether Alibaba Cloud deliberately did not notify and tried to cover up the problem.
Will I still use Alibaba Cloud?
I Will. As the largest cloud service provider in China and one of the top cloud service providers in the world, I have no doubts about Alibaba Cloud’s technical strength. I now use Alibaba Cloud mainly for the CN2 boutique network of Alibaba Cloud Hong Kong, which is used for cross-border data (the price is 3 yuan/GB). There are currently no alternatives in this regard. I have also considered the dedicated line, but it is too expensive to afford.
However, I will not put my core business on Alibaba Cloud. I feel more at ease on AWS. The Alibaba Cloud Hong Kong downtime only affected my website for a short while, and it was precisely because I did not put my core business on Alibaba Cloud.
How does this site achieve high availability?
Very simple, this site uses servers from four different service providers in four regions:
- German OVH
- Beijing AWS
- Hong Kong Alibaba Cloud
- US Google Cloud
And this site is a purely static site. After the site is built, the build products will be synchronized to the four servers respectively, and there is no concept of a master server. This site uses GeoDNS to resolve visitors to the nearest server to reduce latency. After the Alibaba Cloud Hong Kong server goes down, you only need to stop responding and parsing. Originally, the Asia-Pacific region was resolved to Hong Kong, but now Asia is resolved to Beijing, Australia is resolved to the United States, and these users are diverted to available servers.
This site also uses the Health Check function of Route 53, which can monitor the running status of the host in near real time, and automatically stop responding and analyzing when the running status is found to be abnormal. Currently, my site detects and recognizes the exception within a minute of it happening, and stops responding to parsing. The time of relevant DNS records is set at 120 seconds, so when the service is unavailable, the user will not be affected for more than 3 minutes.